Billing
For more information about plans, or to contact us for Enterprise plans, visit our pricing page.
GlareDB offers the following self-service plans:
| Free | Pro | |
|---|---|---|
| Data Processed | 256 GB per month | Unlimited: $7 per TB |
| Storage | Up to 10 GB (total) | Unlimited: $23 per TB |
| Compute | Fully serverless | Fully serverless |
| Deployments | 1 | Up to 5 |
| Organization | Up to 5 members | Up to 30 members |
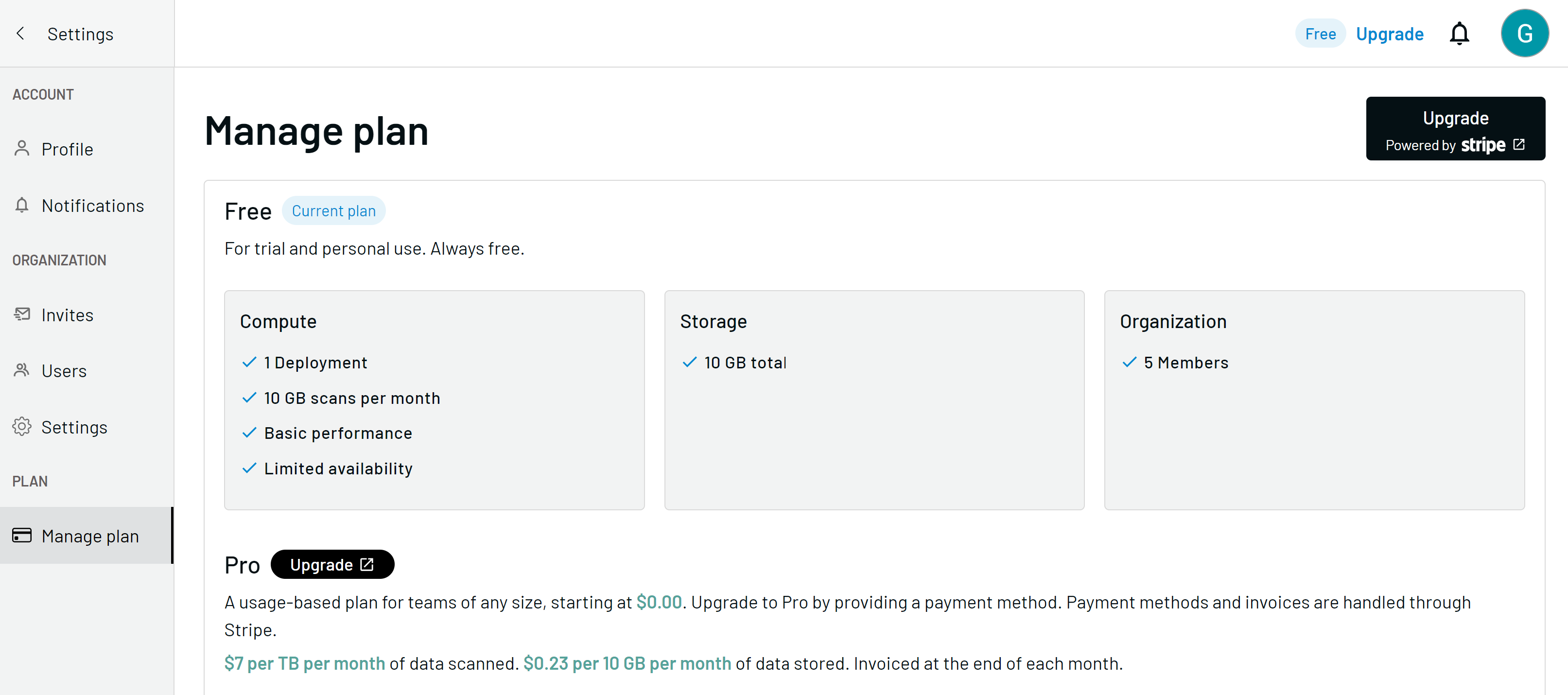
Upgrade to GlareDB Pro
To upgrade to GlareDB Pro, click the Upgrade link at the top right of the page, or use the avatar dropdown menu to navigate to Settings > Manage plan.
From there, click the Upgrade button on the page to begin checkout. Checkout is handled through Stripe. After checkout success, you will be redirected to GlareDB Cloud. A Pro badge appears at the top right. No other actions are required: the features of GlareDB Pro are immediately available.
Downgrade subscription
To downgrade, use the avatar dropdown menu to navigate to Settings and then Manage plan. From this page, click Cancel subscription. Cancellation is handled by Stripe. On success, you will be redirected back to GlareDB Cloud. No other actions are required.
FAQs
How much does it cost? Are there any commitments?
There is no minimum commitment. The plan is entirely pay-for-what-you-use. If your usage falls within the free limits, then you aren’t charged.
- $7 per TB of data processed
- $23 per TB of data stored
How does billing work?
Invoices are created at the end of the month. Depending on your timezone, you will receive it either on the last day of the month or the first day of the following month.
What if I use all the storage in the free tier?
Your sessions will become read-only. To write more data, either drop existing native tables or upgrade to the Pro plan.
How do I know how much data will be processed per query?
GlareDB Cloud records the amount of data read and the size of the output written per query. EXPLAIN reports expected query input size and is a good estimation. Some storage formats are more efficient for limiting the amount of data a query needs to read: Parquet only needs to read the data in the exact field read, and can skip all other columns and data, while queries for PostgreSQL and MySQL are pushed-down to their respective backing stores.