Using GlareDB in Hyperquery
Hyperquery is a data notebook built for speed, visibility, and collaboration. Hyperquery provides the ability to write and execute SQL queries or Python cells directly within a rich graphical interface.
Running GlareDB in Hyperquery
To get started, select an existing notebook, or create a new one.
To install GlareDB in the notebook type /, then select Python block. This will place a new block for executing Python in the notebook, which will be used to to install the GlareDB Python library.
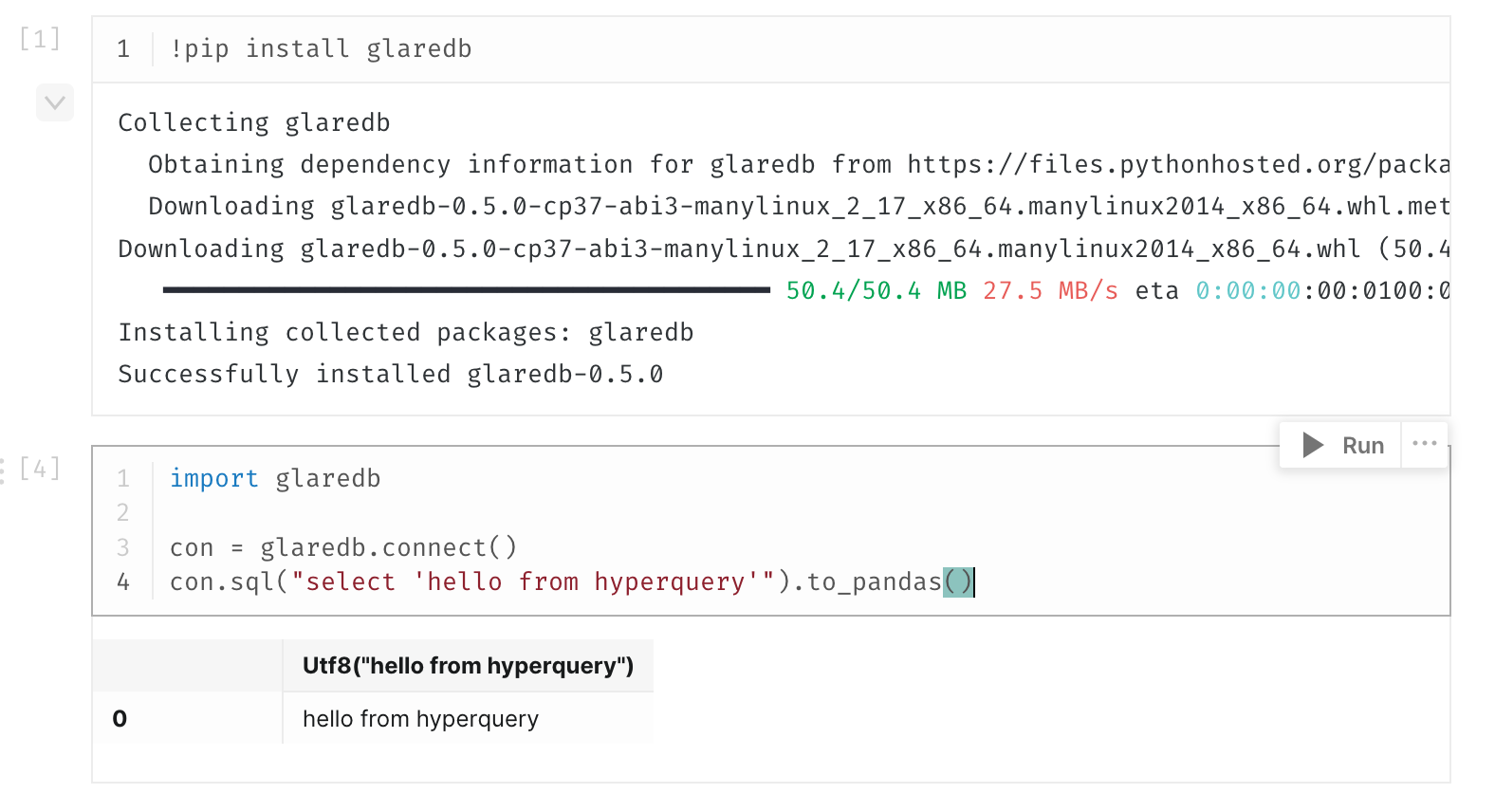
Execute the following command in the code block:
pip install glaredb
Next, in a new Python block, import and use GlareDB:
import glaredb
con = glaredb.connect()
con.sql("SELECT 'hello from hyperquery';").to_pandas()
Pandas is in scope. GlareDB provides interop with both Pandas and Polars dataframe libraries. For more information, refer to GlareDB Python documentation.
Executing SELECT 'hello from hyperquery'; will produce output like:
Connecting to GlareDB Cloud from Hyperquery
GlareDB Cloud features fully-managed instances of GlareDB, enabling you to access your data in notebooks, dashboards and applications. You can sign up here. If you’re a new user, a deployment is automatically created for you. To get connection details for the deployment, click the Connect button then select the Python tab. This will provide a connection URI that you can use when connecting via the Python library.
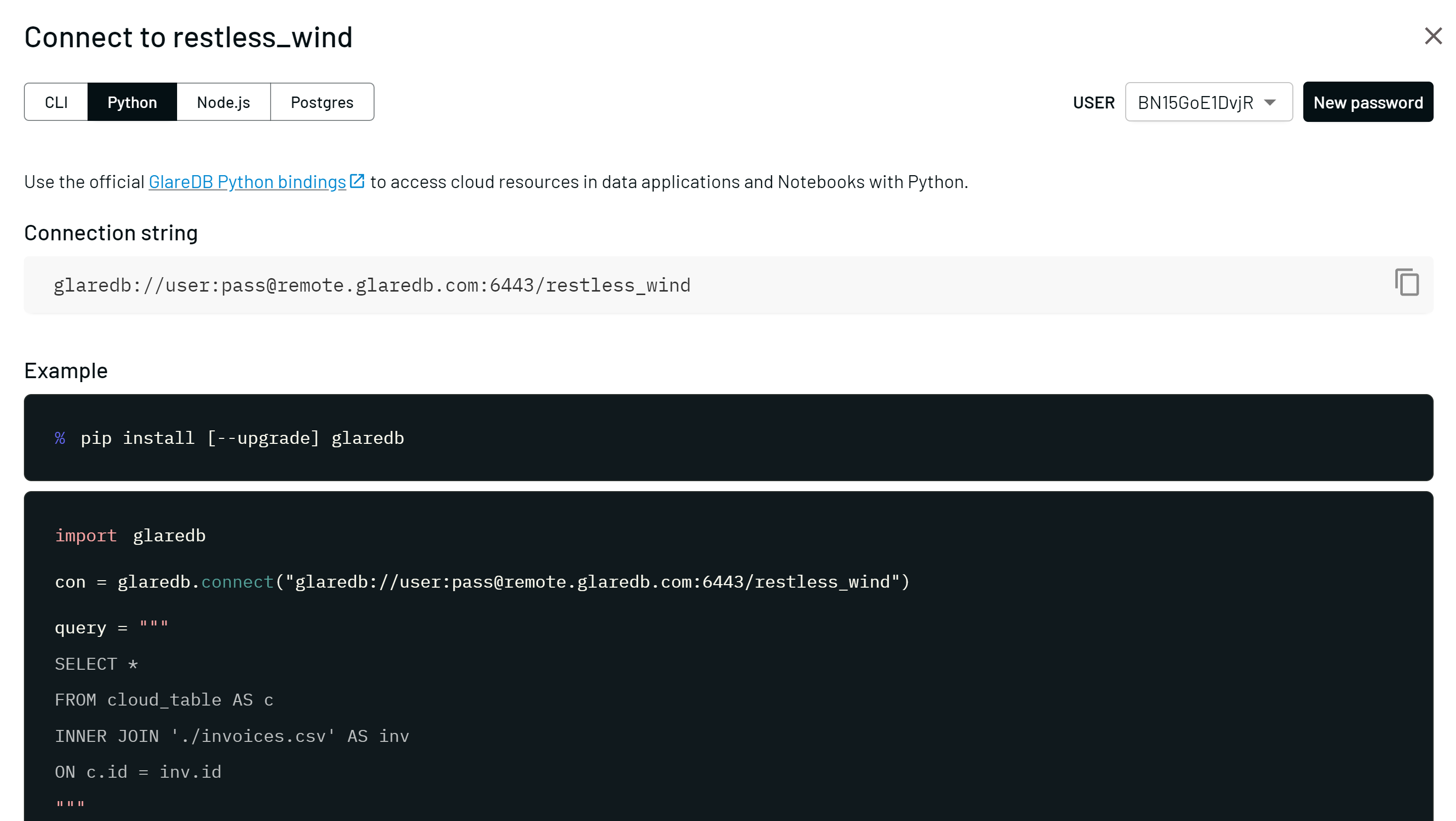
In a Python block, use the connection URI when calling GlareDB.connect:
import glaredb
cloud_uri = "glaredb://user:password@org.remote.glaredb.com:6443/db_name"
con = glaredb.connect(cloud_uri)
Hyperquery has access to all of the resources in the GlareDB Cloud deployment through Hybrid Execution. Data in the notebook, including Pandas and Polars dataframes can be joined with data in GlareDB Cloud.